| Previous | Table of Contents | Next |
This is why a two-phase commit is called as it is; for a transaction to be final in a two-phase commit, aside from the initial single database commit, a second validation must occur with remote sites before the transaction can be completed. Thus we have a two-phase validation.
The difference between these two phases is that the first commit is part of ANSI SQL. It can be defined explicitly in relational algebra; the second phase of a commit is more vendor dependent and flexible regarding what constitutes validation of data transfer to remote sites.
Oracle has actually implemented a new “distributed transaction protocol” that is actually just a more efficient form of the traditional two-phase commit.
Conflict Resolution
Just as with people performing different tasks at remote locations for the same company, computers need to be explicitly taught the procedures for coordinating their tasks over a network. When two computers produce conflicting results, a virtual policy must be in place to first find and then resolve mistakes that might arise when work performed at two locations is not consistent with local or corporatewide business rules.
Types of Conflicts
Because we are creating one virtual database out of N number of database schemas, this virtual database must obey all the relational rules of conduct for us to consider the replication valid. For instance, we cannot have two users on separate sites both inserting the same unique primary key.
Because this second part of the two-phase commit is more nebulous, we must make sure that our replicated system adheres to the strict standards that keep a relational database from turning into sets of chaotic data.
In an example where two separate nodes of our distributed database change the same data, we have a potential for disaster. In Oracle’s replication, any change by any node on a table causes Oracle to store the old and new values for the row.
To identify rows across a distributed database, Oracle cannot use a rowid that is only a physical identifier of a row, unique only for a given node of the distributed database. Across nodes, rowid is not unique. Oracle instead needs to use the actual primary key definition of the table to perform uniqueness operations.
With the information of a table’s primary key and with the old and new values of a data change, Oracle can automatically detect three types of conflicts:
- 1. Uniqueness Conflicts—An example of this might be that two sales sites sell a new corporate customer a bunch of Star Trek trinkets on the same day. Both applications, for example, in New York and San Francisco insert a new row for this customer in the customer table. If the same unique identifier is used, such as Tax ID, there now exists two duplicate rows in the virtual distributed database. This error must be resolved.
- 2. Update Conflicts—In this case, we have two of the separate database servers performing changes on a row before they are reconciled with one another.
An example in our Star Trek trinket factory in Figure 16.11 would be if an order in Hong Kong reduced a shipping inventory in San Francisco while an order in San Francisco also reduced the same inventory. Say the combined order was for 150 units and yet we only had 140 units in our warehouse.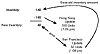
Figure 16.11. We try to order 50 units for San Francisco. If we don’t yet “see” the Hong Kong transaction, we will pledge to ship 50 units when we have only 40 units.
The Hong Kong site issues the following SQL:update inventory set amt = amt - 100 where trinket_type = 'KLINGON DOLL’
Because of an unrelated order in San Francisco the inventory is lowered again and this second transaction is allowed to go through even though we now possess only 40 units after the preceding sale:update inventory set amt = amt - 50 where trinket_type = 'KLINGON DOLL’
In the second case, the computer still thinks that inventory is at 140, not at 40, where it should be set after the first order.
Oracle would compare the following values.
Oracle solves this by using procedures at the receiving site to detect these forms of update conflicts.- 3. Delete Conflicts—A delete conflict occurs if a row is deleted at one site but the values of this row’s remote replicated relatives are different. This occurs if someone cancels (deletes) an order at one site—for example, in New York—and later another person updates that row in Hong Kong not knowing it was deleted.
- 2. Update Conflicts—In this case, we have two of the separate database servers performing changes on a row before they are reconciled with one another.
)
){kind=link}
Managing Update Conflicts
To manage an update conflict, we first assign sub-sets of our column definitions that are being replicated into column groups. These are simply logical groups of column definitions that enable you to specify exact rules for the resolution of a conflict.
With numeric data, many times we just allow the changes to be aggregated without any further logic. With character data, we might need a timestamp. We cannot sum characters logically. For instance if special instructions were left with both the San Francisco office and the Hong Kong office for a particular order, we might just decide to take the instruction with the most current timestamp.
Here are some resolution strategies that you can set for Oracle to use after you create column groups to define your replicated data:
- 1. Apply the data with the latest timestamp.
- 2. Apply all data additively.
- 3. Apply the maximum value if the column is being increased.
- 4. Apply the data with the earliest timestamp.
- 5. Apply the minimum value.
- 6. Apply the maximum value.
- 7. Apply the value from the highest priority site.
- 8. Apply the value assigned the highest priority.
- 9. Apply the average value.
- 2. Apply all data additively.
Creating Column Groups
When we consider a conflict strategy, we should always look toward the most current release of Oracle’s Server and Replication facility. The method to create a strategy is based again with calls to PL/SQL packages, thus the system is very flexible and Oracle might have added new options.
When we have a strategy in mind for the replication of a certain set of columns, we can define that column group. Let’s define a column group for UNIT_PRICE and QUANTITY_SOLD. To do this, we call a procedure:
DBMS_REPCAT.MAKE_COLUMN_GROUP(‘SALES’, ‘SALES’, ‘MYGROUP’, ‘unit_price,quantity_sold’);
| Previous | Table of Contents | Next |